



Στην συζήτηση που κάναμε για την διαφορά του ερευνητή (researcher) από τον μηχανικό (engineer) o συνφορουμίτης manos_89 εξέφρασε την παρακάτω άποψη:
Δυστυχώς από άλλα πεδία δεν μπορώ να ξέρω αρκετά και ένα deep dive θα μου έπαιρνε αρκετές εβδομάδες ώστε να μπορώ να γράψω κάτι σχετικά χρήσιμο όμως μίας και ο συμφορουμίτης σχολίασε συγκεκριμένα το computer science που είναι το πεδίο έρευνας μου νομίζω πως μπορώ να γράψω πέντε πράγματα που ίσως βοηθήσουν λίγο στην λύση αυτής της παρεξήγησης.
Το κείμενο αυτό θα έχει μερικές ορολογίες που ίσως ξενίσουν λίγο αναγνώστες που δεν έχουν σχέση/βαριούνται να ψάξουν, θα προσπαθήσω να το παρουσιάσω όσο πιο απλά γίνεται. Αν κάτι δεν είναι ξεκάθαρο ευχαρίστως να απαντήσω σε οποιαδήποτε ερώτηση. Προσπάθησα να κρατήσω αρκετά ελληνικά στην ορολογία και μπορεί σε μερικούς που γνωρίζουν να φαίνονται αστεία. Από παλιά ποστ έχω κρατήσει ότι προτιμάται η χρήση των ελληνικών και γι'αυτό το κάνω. Επίσης θέλω να κάνω σαφές ότι ενώ απλά ξεκίνησα από το σχόλιο του manos_89, το ποστ αυτό δεν αφορά εκείνον προσωπικά, είναι μία γενική θεώρηση.
Θα αρχίσω με ένα μικρό γραφικό παράδειγμα (εδώ το ολόκληρο: https://matt.might.net/articles/phd-school-in-pictures/) που έχει να κάνει με τα χρόνια του PhD αλλά νομίζω μπορεί να γενικευτεί στην έρευνα γενικότερα.
Ας φανταστούμε όλη την ανθρώπινη γνώση σαν έναν κύκλο:

Και ας χρωματίσουμε το πόσα μαθαίνουμε στο σχολείο, με μπλε το δημοτικό, με πράσινο το λύκειο, με ροζ το πτυχίο, μετά το μεταπτυχιακό. Με κόκκινο είναι το τι μαθαίνουμε διαβάζοντας επιστημονικές εργασίες που μας φέρνουν στην άκρη της γνώσης.
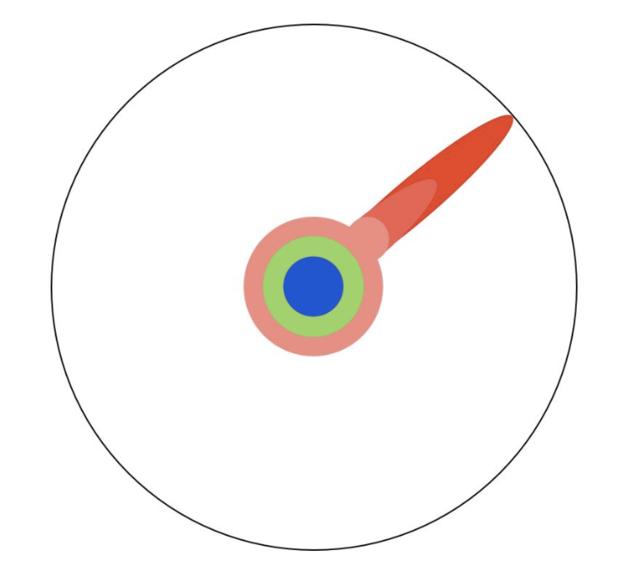
Όταν φτάσουμε εκεί συγκεντρώνουμε την προσπάθεια μας:
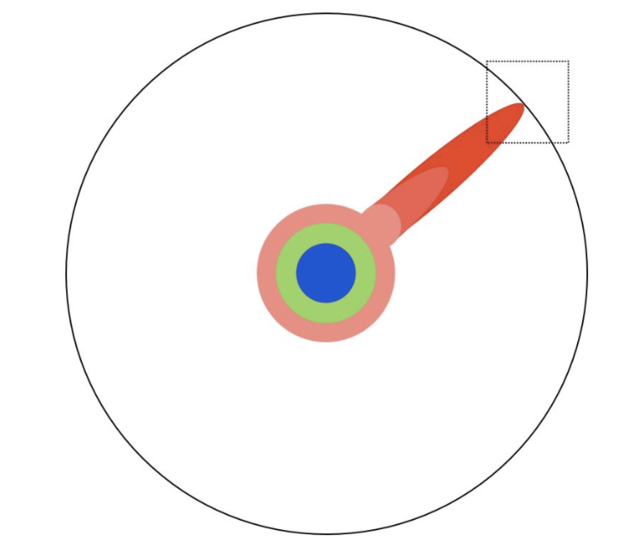
Και παλεύουμε να σπρώξουμε για μερικά χρόνια

Ώσπου τελικά τα καταφέρνουμε:
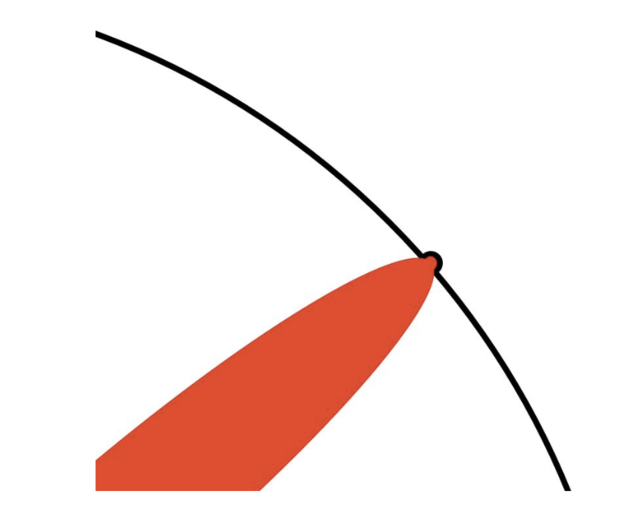
Όμως είναι σημαντικό να μην ξεχνάμε την μεγάλή εικόνα
Πώς λειτουργεί η έρευνα και γιατί παρεξηγείται
Η κριτική που έκανε ο manos_89 ότι δηλαδή η έρευνα "κυνηγάει χρηματοδότηση και δεν έχει κανένα επιστημονικό ενδιαφέρον" αποκαλύπτει μια θεμελιώδη παρανόηση. Αντιμετωπίζεται η έρευνα σαν να είναι προιόν σε παραγωγική αλυσίδα. Σαν να μπαίνει μια ερώτηση στη μία άκρη και να βγαίνει μια πατέντα στην άλλη. Αλλά η αλήθεια είναι ότι η έρευνα δουλεύει σε συνθήκες θεμελιώδους αβεβαιότητας:
- Ξεκινάς με ένα πρόβλημα που μπορεί να μην έχει λύση.
- Δοκιμάζεις ιδέες που μπορεί να αποτύχουν όλες.
- Οι επιτυχίες σου κρίνονται σε σχέση με προηγούμενη βιβλιογραφία (που απαιτεί μεγάλο κόπο για να κατανοήσεις πρώτα).
- Και όταν τελικά βγάλεις κάτι, δεν είναι πάντα κατανοητό αμέσως.
Ο στόχος δεν είναι να "πιάσεις στόχους", αλλά να επεκτείνεις την ανθρώπινη γνώση σε έναν τομέα που συχνά δεν ξέρει καν τι δεν ξέρει.
Η ερευνητική διαδικασία στην πράξη
Για να γίνει πιο απτό, ας σκεφτούμε πώς κινείται ένα μέσο project στην πληροφορική:
1. Βιβλιογραφική ανασκόπηση: διαβάζεις δεκάδες papers, για να βρεις πού βρίσκεται η άκρη της γνώσης.
2. Διατύπωση υπόθεσης: κάνεις μια εικασία, πχ ότι ένας νέος αλγόριθμος μπορεί να είναι πιο αποδοτικός.
3. Απόδειξη/πείραμα/μοντελοποίηση: γράφεις τύπους, προσπαθείς να κάνεις αναγωγές, υπολογίζεις bounds ή προγραμματίζεις.
4. Peer review και απόρριψη: πολλές φορές απορρίπτεται το paper και πάμε πάλι.
5. Παρουσίαση, ανατροφοδότηση, νέα ιδέα.
Αυτό το οικοσύστημα δεν έχει καμία σχέση με το πώς αντιλαμβάνονται την παραγωγή αξίας όσοι βρίσκονται σε ερευνητικό περιβάλλον και περίμεναν είτε χρήματα είτε εντυπωσιακά αποτελέσματα.
"Δεν καταλαβαίνω = δεν έχει αξία"
Πολλές φορές, η απαξίωση της έρευνας προκύπτει από έναν συγκαλυμμένο εγωκεντρισμό. Επειδή κάτι είναι δυσνόητο, επειδή απαιτεί μεγάλο θεωρητικό υπόβαθρο ή επειδή δεν παράγει κάτι άμεσα χρήσιμο για εμένα το βγάζω άχρηστο. Αυτή η στάση θυμίζει ανθρώπους που λένε ότι η μοντέρνα τέχνη "είναι κουράδες" επειδή δεν την καταλαβαίνουν. Αλλά αν δεχτούμε ότι η επιστήμη είναι κοινό κτήμα και συλλογική προσπάθεια, τότε δεν χρειάζεται εγώ προσωπικά να δω το νόημα σε κάθε paper. Χρειάζεται να εμπιστευτώ ότι λειτουργεί ένα σύστημα αξιολόγησης, επανάληψης, απόρριψης και αναθεώρησης που στατιστικά παράγει γνώση.
"Οι ερευνητές κυνηγάνε χρηματοδότηση"
Ναι, η χρηματοδότηση είναι μέρος της ερευνητικής διαδικασίας. Αλλά αυτό ισχύει για κάθε πρακτική ανθρώπινη δραστηριότητα. Το ότι πρέπει να γράψεις grant proposals, να διεκδικήσεις πόρους, να δώσεις λόγο για το ερευνητικό σου πρόγραμμα, δεν σημαίνει ότι η δουλειά σου είναι κενή περιεχομένου. Βασικά συμβαίνι ακριβώς το αντίθετο. Η ερευνητική χρηματοδότηση σε καλεί να τεκμηριώσεις γιατί το ερώτημα που θέτεις αξίζει να απαντηθεί, όχι απαραίτητα γιατί θα παράγει προιόν. Και εδώ εντοπίζεται η διαφορά με το R&D σε εταιρείες. Δεν στοχεύει στο άμεσο κέρδος αλλά στην επέκταση της γνώσης ακόμα κι αν δεν ξέρεις εκ των προτέρων πού θα οδηγήσει.
Αν θέλουμε να καταλάβουμε τι σημαίνει αυτό, ας ξεκινήσουμε από κάτι που ίσως ενδιαφέρει γενικότερα λόγω του hype. ΑΙ και Large Language Models.
Από μικρά βήματα στα LLMs
Το να μιλάς με ένα Large Language Model σήμερα είναι σχεδόν μαγικό. Αλλά η μαγεία αυτή δεν γεννήθηκε προχθές. Είναι απλά ένας ακόμα κρίκος μιας αλυσίδας ερευνητικών βημάτων που ξεκινά αρκετά παλιά αλλά για να μην κάνουμε πλήρη ιστορική αναδρομή, ας το πιάσουμε από τις αρχές της δεκαετίας του 1990. Στις αρχές εκείνης της δεκαετίας, το Latent Semantic Analysis (LSA) ήταν απλά ένα εργαλείο για document retrieval. Χρησιμοποιούσε κάποιες τεχνικές από αριθμητική ανάλυση ώστε να αναπαραστήσει λέξεις και κείμενα σε κοινό διανυσματικό χώρο. Κανείς δεν είχε στο νου του GPTs, αλλά η ιδέα ότι οι λέξεις μπορούν να αναπαρίστανται ως σημεία σε ένα χώρο ήταν η αρχή για όλα τα embeddings που ακολούθησαν. Το 2013, το word2vec άλλαξε εντελώς το πεδίο του Natural Language Processing (NLP). Ο Mikolov et al ( ) χρησιμοποίησαν νευρωνικά δίκτυα για να μάθουν context-aware embeddings. Από εκεί έχουμε τη διάσημη εξισωση: v("king") - v("man") + v("woman") = v("queen"). Δεν έλυνε κάποιο πρακτικό πρόβλημα, αλλά έδειχνε μια νέα ας το πούμε γλωσσική γεωμετρία (δεν ξέρω αν είναι δόκιμος ο όρος). Το 2014, ο Bahdanau μίλησε για το attention στο machine translation. Ο decoder μπορούσε να εστιάζει δυναμικά σε διαφορετικές κρυφές καταστάσεις του encoder κάτι που έλυσε το πρόβλημα μεγάλων προτάσεων και άνοιξε δρόμο για πιο γενικά μοντέλα. Το 2017, το "Attention is All You Need" κράτησε μόνο το attention. Ο transformer έκανε το training παραλληλίσιμο και μαζί με άλλα μπλιπλίκια, η πορεία ήταν θέμα κλίμακας και βελτίωσης. Κάθε βήμα φαινόταν απλά "τεχνικό" αλλά όλα μαζί όμως έκαναν τα LLMs εφικτά.
) χρησιμοποίησαν νευρωνικά δίκτυα για να μάθουν context-aware embeddings. Από εκεί έχουμε τη διάσημη εξισωση: v("king") - v("man") + v("woman") = v("queen"). Δεν έλυνε κάποιο πρακτικό πρόβλημα, αλλά έδειχνε μια νέα ας το πούμε γλωσσική γεωμετρία (δεν ξέρω αν είναι δόκιμος ο όρος). Το 2014, ο Bahdanau μίλησε για το attention στο machine translation. Ο decoder μπορούσε να εστιάζει δυναμικά σε διαφορετικές κρυφές καταστάσεις του encoder κάτι που έλυσε το πρόβλημα μεγάλων προτάσεων και άνοιξε δρόμο για πιο γενικά μοντέλα. Το 2017, το "Attention is All You Need" κράτησε μόνο το attention. Ο transformer έκανε το training παραλληλίσιμο και μαζί με άλλα μπλιπλίκια, η πορεία ήταν θέμα κλίμακας και βελτίωσης. Κάθε βήμα φαινόταν απλά "τεχνικό" αλλά όλα μαζί όμως έκαναν τα LLMs εφικτά.
Λίγο πιο γενικά ιστορικά
Μετασχηματισμός Fourier
Το 1965, οι Cooley και Tukey παρουσίασαν τον Fast Fourier Transform (FFT). Στην εποχή τους, ήταν καθαρά μαθηματικό/υπολογιστικό εργαλείο και για δεκαετίες, ελάχιστοι εκτός μαθηματικών και μηχανικών σήματος ενδιαφέρθηκαν. Σήμερα, ο FFT είναι κρυμμένος σε κάθε JPEG, MP3, και streaming. Όταν συμπιέζεις μια εικόνα ή ένα τραγούδι, οι συντελεστές Fourier κάνουν τη δουλειά. Χωρίς τη θεωρητική δουλειά του 65, η ψηφιακή εικόνα και ήχος δεν θα ήταν εφικτά όπως τα ξέρουμε.
Θεωρία Ramsey και distributed computing
Η θεωρία Ramsey από τα 30s εξετάζει πόσο μεγάλο πρέπει να είναι ένα σύνολο για να εγγυάται ότι θα εμφανιστεί μια συγκεκριμένη δομή. Για δεκαετίες ήταν καθαρά θεωρητική. Βασικά ήταν χρήσιμη σε combinatorics και γραφήματα. Σήμερα, τα θεμελιώδη αποτελέσματά της εφαρμόζονται στην ασφάλεια distributed συστημάτων και στην ανοχή σε σφάλματα.
Θεωρία πληροφορίας
Το 1948, ο Claude Shannon δημοσίευσε το "A Mathematical Theory of Communication". Δεν υπήρχε καμία εμπορική εφαρμογή. Τα τηλέφωνα ήταν αναλογικά και φυσικά το internet δεν υπήρχε. Σήμερα, κάθε μορφή ψηφιακής επικοινωνίας (WiFi, 4G, 5G, Internet) στηρίζεται στις αρχές του Shannon. Όλη η ψηφιακή εποχή χρωστά σε έναν άνθρωπο που τότε έγραφε "άχρηστη" μαθηματική θεωρία.
Γενικά
Markov Chains (1906) -> PageRank, Google Search
Graph theory (Euler, 1736) -> δίκτυα, routing, logistics
Κρυπτογραφία: το παιχνίδι της υπομονής
Αυτό είναι το δικό μου πεδίο οπότε μπορώ να μιλήσω με πολύ μεγαλύτερη ευκολία και να απαντήσω σε ερωτήσεις. Η κρυπτογραφία δείχνει ακόμη πιο καθαρά γιατί η έρευνα δεν πρέπει να κρίνεται μόνο με βάση το άμεσο αποτέλεσμα.
Το 1976, οι Diffie και Hellman παρουσίασαν τον πρώτο αλγόριθμο δημόσιας ανταλλαγής κλειδιών. Δηλαδή για πρώτη φορά μπορούσες να ανταλλάξεις κλειδιά για κρυπτογράφηση χωρίς να χρειάζεται να συναντήσεις κάποιον. Είναι μία πολύ έξυπνη ιδέα, αλλά πρακτικά πολύ αργή. Το 1977, το RSA έκανε το ίδιο για την κρυπτογράφηση. Δηλαδή μπορούσες να πάρεις το δημόσιο κλειδί κάποιου και να του στείλεις ένα μυστικό μήνυμα και μόνο εκείνος με το ιδιωτικό κλειδί θα μπορούσε να το διαβάσει. Και τα δύο έμειναν για χρόνια σαν "θεωρητικές πολυτέλειες". Σήμερα είναι τα θεμέλια κάθε ασφαλούς σύνδεσης σε οτιδήποτε κάνεις στο internet.
Στα 80ς είχαμε μία τρομερή ανακάλυψη. Τις αποδείξεις μηδενικής γνώσης. Γενικά αν θέλω να αποδείξω κάτι σε κάποιον, τότε ο πιο έυκολος τρόπος είναι να του δείξω αυτό το κάτι. Τι γίνεται όμως αν δεν θέλω να αποκαλύψω αυτό το "κάτι"; Αν είναι μυστικό; Τα Zero Knowledge Proofs έδειξαν ότι μπορείς να αποδείξεις ότι ξέρεις κάτι χωρίς να το αποκαλύψεις. Για δεκαετίες ήταν απλά θεωρία. Σήμερα είναι τεχνολογικό θεμέλιο σε blockchains, ψηφιακές ταυτότητες, ιδιωτικές ψηφοφορίες κλπ.
Στα 90ς ο γίγαντας Ajtai παρουσίασε μία συγκεκριμένη δυσκολία σε ένα μαθηματικό πρόβλημα. Το 2005, ο Regev χρησιμοποίησε αυτό το γεγονός και πρότεινε το Learning With Errors, που έγινε βάση για post-quantum κρυπτογραφία. Δηλαδή για κρυπτογραφία που θα ήταν ασφαλής απέναντι σε κβαντικούς υπολογιστές. Η έρευνα πάνω σε αλγόριθμους κβαντικών υπολογιστών είναι ακόμα ένα παράδειγμα έρευνας που *ίσως* βρει έδαφος σε αρκετά χρόνια από τώρα.
Το 2009, ο Gentry παρουσίασε το Fully Homomorphic Encryption δηλαδή να μπορούμε να υπολογίσουμε οποιαδήποτε συνάρτηση σε κρυπτογραφημένα δεδομένα. Παράλληλα, το multi-party computation εξελίχθηκε από "α κοίτα τι μπορώ να κάνω εντελώς θεωρητικά" Yao (1982) μέχρι τώρα που έχουμε libraries, καθιστώντας ασφαλείς υπολογισμούς πραγματικότητα.
Κάθε μία από αυτές τις τεχνολογίες ήταν κάποτε "άχρηστη". Τώρα είναι αόρατες υποδομές του Internet.
Η έρευνα ως κατανόηση, όχι μόνο ως προiόν
Η οικονομική λογική θέλει την έρευνα να έχει "απόδοση επένδυσης". Αλλά η επιστήμη δεν γεννήθηκε για να παράγει προiόντα. Γεννήθηκε για να κατανοεί τον κόσμο. K κάνουμε υποθέσεις, τις ελέγχουμε, αποτυγχάνουν, μαθαίνουμε. Ο Kuhn μας λέει ότι τα μεγάλα άλματα (paradigm shifts) έρχονται σπάνια, και προετοιμάζονται από χρόνια κανονικής, "βαρετής" επιστήμης. Ο Feyerabend τόνισε ότι η έρευνα χρειάζεται ελευθερία να κινείται και σε "άχρηστες" κατευθύνσεις γιατί δεν ξέρουμε από πού θα έρθει η επόμενη ιδέα.
Η εικασία του Collatz μπορεί να μην φτιάξει ποτέ καλύτερα κινητά. Αλλά η προσπάθεια να λυθεί μπορεί να φέρει νέα εργαλεία στη θεωρία αριθμών, που θα βρουν εφαρμογή εκεί που δεν το περιμέναμε. Btw θεωρία αριθμών πρέπει να μελετούσαν οι άνθρωποι για 2000 χρόνια (από αρχαία Ελλάδα μέχρι Fermat, Euler, Gauss) μέχρι να βρει εφαρμογή στο RSA που λέγαμε πιο πάνω.
Για να το κάνω και λίγο προσωπικό, στην τελευταία μου δημοσίευση δημιουργήσαμε έναν καινούριο τύπο Pseudorandom Generator (γεννήτρια τυχαιότητας). H βασική εφαρμογή του είναι πως είναι ένα θεωρητικά πιο "απλό" αντικείμενο από τους παλιούς και άρα μπορείς να έχεις κάποια αποτελέσματα με μικρότερη πολυπλοκότητα. Είναι χρήσιμο αυτό; Δεν ξέρω, ο καιρός θα δείξει. Θα χρησιμοποιηθεί άμεσα στο UNIX για να παράγει τυχαίους αριθμούς; Φυσικά και όχι.
Ένα οικοσύστημα ιδεών
Όταν κρίνουμε την έρευνα από το σήμερα, το 99% της μπορεί να φαίνεται ασήμαντο. Αλλά χωρίς αυτό το 99%, δεν θα υπήρχε το 1% που αλλάζει τα πάντα. Και επειδή δεν ξέρουμε ποιο είναι αυτό το 1%, πρέπει να καλλιεργούμε ολόκληρο το οικοσύστημα.
Η έρευνα είναι ο σπόρος και το engineering είναι ο φρούτο. Κι αν κοιτάμε μόνο τα φρούτα τότε ξεχνάμε ότι κάποιος έπρεπε να φυτέψει το δέντρο χρόνια πριν.
Ευχαριστώ όποιον διάβασε Ώς συνήθως δεκτές προτάσεις για βελτίωση γραψίματος, ύφους, περιεχομένου κλπ Έχω παραλείψει αρκετά πράγματα ειδικά στο κομμάτι της σημασίας της κατανόησης του κόσμου γύρω μας αλλά επίσης έχω μάθει ότι όταν γίνεται πολύ μεγάλο το κείμενο τότε χάνω αρκετό κόσμο κάπου στη μέση
Ώς συνήθως δεκτές προτάσεις για βελτίωση γραψίματος, ύφους, περιεχομένου κλπ Έχω παραλείψει αρκετά πράγματα ειδικά στο κομμάτι της σημασίας της κατανόησης του κόσμου γύρω μας αλλά επίσης έχω μάθει ότι όταν γίνεται πολύ μεγάλο το κείμενο τότε χάνω αρκετό κόσμο κάπου στη μέση
Δεν είναι η πρώτη φορά που το ακούω αυτό και μάλιστα είναι και είναι και κάποιου είδους στερεότυπο ο ακαδημαικός που δεν έχει καμία επαφή με τον πραγματικό κόσμο. Είναι μια άποψη που λέγεται. Ακούγεται κυνική και διορατική, αλλά στην πραγματικότητα είναι νομίζω χτισμένη πάνω σε μια παρεξήγηση. Κρίνει την έρευνα σαν να είναι γραμμή παραγωγής προιόντων διότι η άποψη είναι πως πρέπει να δώσει ένα εμπορικό αποτέλεσμα στα επόμενα λίγα χρόνια. Αν δούμε όμως την ιστορία της επιστήμης τότε νομίζω είναι ξεκάθαρο πως οι τεχνολογίες που σήμερα θεωρούμε δεδομένες σπάνια προέκυψαν από ένα ξαφνικό άλμα. Ήταν το αποτέλεσμα δεκαετιών μικρών βημάτων, θεωρητικών ιδεών, "άχρηστων" πειραμάτων και σταθερής επίμονης δουλειάς που αθροίστηκε ώσπου να φτάσουμε σε σημείο καμπής.manos_89 έγραψε: ↑Κυρ Αύγ 03, 2025 12:30 amΣαν προγραμματιστής που έχω δουλέψει 2 χρόνια σε πανεπιστήμιο εξωτερικού σε έρευνα, αλλά και από φίλους πληροφορικάριους που δουλεύουν σε γνωστά "ερευνητικά κέντρα", εντός και εκτός ελλάδας, η άποψη μου έχει διαμορφωθεί στο ότι το 99% της έρευνας που γίνεται είναι κουράδες, και το θέτω πολύ επιεικά.
Το ποσοστό είναι κατα προσέγγιση, αλλά όλος ο σκοπός της έρευνας όπως την έχω δει εγώ είναι το κυνήγι της χρηματοδότησης. Καμία ουσία, κανένα επιστημονικό ενδιαφέρον, τίποτα. Zero.
Σε άλλους τομείς, βιολογία, ιατρική και δεν ξέρω και γω που αλλού, το παραπάνω μπορεί να είναι εντελώς διαφορετικό.
Δυστυχώς από άλλα πεδία δεν μπορώ να ξέρω αρκετά και ένα deep dive θα μου έπαιρνε αρκετές εβδομάδες ώστε να μπορώ να γράψω κάτι σχετικά χρήσιμο όμως μίας και ο συμφορουμίτης σχολίασε συγκεκριμένα το computer science που είναι το πεδίο έρευνας μου νομίζω πως μπορώ να γράψω πέντε πράγματα που ίσως βοηθήσουν λίγο στην λύση αυτής της παρεξήγησης.
Το κείμενο αυτό θα έχει μερικές ορολογίες που ίσως ξενίσουν λίγο αναγνώστες που δεν έχουν σχέση/βαριούνται να ψάξουν, θα προσπαθήσω να το παρουσιάσω όσο πιο απλά γίνεται. Αν κάτι δεν είναι ξεκάθαρο ευχαρίστως να απαντήσω σε οποιαδήποτε ερώτηση. Προσπάθησα να κρατήσω αρκετά ελληνικά στην ορολογία και μπορεί σε μερικούς που γνωρίζουν να φαίνονται αστεία. Από παλιά ποστ έχω κρατήσει ότι προτιμάται η χρήση των ελληνικών και γι'αυτό το κάνω. Επίσης θέλω να κάνω σαφές ότι ενώ απλά ξεκίνησα από το σχόλιο του manos_89, το ποστ αυτό δεν αφορά εκείνον προσωπικά, είναι μία γενική θεώρηση.
Θα αρχίσω με ένα μικρό γραφικό παράδειγμα (εδώ το ολόκληρο: https://matt.might.net/articles/phd-school-in-pictures/) που έχει να κάνει με τα χρόνια του PhD αλλά νομίζω μπορεί να γενικευτεί στην έρευνα γενικότερα.
Ας φανταστούμε όλη την ανθρώπινη γνώση σαν έναν κύκλο:
Και ας χρωματίσουμε το πόσα μαθαίνουμε στο σχολείο, με μπλε το δημοτικό, με πράσινο το λύκειο, με ροζ το πτυχίο, μετά το μεταπτυχιακό. Με κόκκινο είναι το τι μαθαίνουμε διαβάζοντας επιστημονικές εργασίες που μας φέρνουν στην άκρη της γνώσης.
Όταν φτάσουμε εκεί συγκεντρώνουμε την προσπάθεια μας:
Και παλεύουμε να σπρώξουμε για μερικά χρόνια
Ώσπου τελικά τα καταφέρνουμε:
Όμως είναι σημαντικό να μην ξεχνάμε την μεγάλή εικόνα
Πώς λειτουργεί η έρευνα και γιατί παρεξηγείται
Η κριτική που έκανε ο manos_89 ότι δηλαδή η έρευνα "κυνηγάει χρηματοδότηση και δεν έχει κανένα επιστημονικό ενδιαφέρον" αποκαλύπτει μια θεμελιώδη παρανόηση. Αντιμετωπίζεται η έρευνα σαν να είναι προιόν σε παραγωγική αλυσίδα. Σαν να μπαίνει μια ερώτηση στη μία άκρη και να βγαίνει μια πατέντα στην άλλη. Αλλά η αλήθεια είναι ότι η έρευνα δουλεύει σε συνθήκες θεμελιώδους αβεβαιότητας:
- Ξεκινάς με ένα πρόβλημα που μπορεί να μην έχει λύση.
- Δοκιμάζεις ιδέες που μπορεί να αποτύχουν όλες.
- Οι επιτυχίες σου κρίνονται σε σχέση με προηγούμενη βιβλιογραφία (που απαιτεί μεγάλο κόπο για να κατανοήσεις πρώτα).
- Και όταν τελικά βγάλεις κάτι, δεν είναι πάντα κατανοητό αμέσως.
Ο στόχος δεν είναι να "πιάσεις στόχους", αλλά να επεκτείνεις την ανθρώπινη γνώση σε έναν τομέα που συχνά δεν ξέρει καν τι δεν ξέρει.
Η ερευνητική διαδικασία στην πράξη
Για να γίνει πιο απτό, ας σκεφτούμε πώς κινείται ένα μέσο project στην πληροφορική:
1. Βιβλιογραφική ανασκόπηση: διαβάζεις δεκάδες papers, για να βρεις πού βρίσκεται η άκρη της γνώσης.
2. Διατύπωση υπόθεσης: κάνεις μια εικασία, πχ ότι ένας νέος αλγόριθμος μπορεί να είναι πιο αποδοτικός.
3. Απόδειξη/πείραμα/μοντελοποίηση: γράφεις τύπους, προσπαθείς να κάνεις αναγωγές, υπολογίζεις bounds ή προγραμματίζεις.
4. Peer review και απόρριψη: πολλές φορές απορρίπτεται το paper και πάμε πάλι.
5. Παρουσίαση, ανατροφοδότηση, νέα ιδέα.
Αυτό το οικοσύστημα δεν έχει καμία σχέση με το πώς αντιλαμβάνονται την παραγωγή αξίας όσοι βρίσκονται σε ερευνητικό περιβάλλον και περίμεναν είτε χρήματα είτε εντυπωσιακά αποτελέσματα.
"Δεν καταλαβαίνω = δεν έχει αξία"
Πολλές φορές, η απαξίωση της έρευνας προκύπτει από έναν συγκαλυμμένο εγωκεντρισμό. Επειδή κάτι είναι δυσνόητο, επειδή απαιτεί μεγάλο θεωρητικό υπόβαθρο ή επειδή δεν παράγει κάτι άμεσα χρήσιμο για εμένα το βγάζω άχρηστο. Αυτή η στάση θυμίζει ανθρώπους που λένε ότι η μοντέρνα τέχνη "είναι κουράδες" επειδή δεν την καταλαβαίνουν. Αλλά αν δεχτούμε ότι η επιστήμη είναι κοινό κτήμα και συλλογική προσπάθεια, τότε δεν χρειάζεται εγώ προσωπικά να δω το νόημα σε κάθε paper. Χρειάζεται να εμπιστευτώ ότι λειτουργεί ένα σύστημα αξιολόγησης, επανάληψης, απόρριψης και αναθεώρησης που στατιστικά παράγει γνώση.
"Οι ερευνητές κυνηγάνε χρηματοδότηση"
Ναι, η χρηματοδότηση είναι μέρος της ερευνητικής διαδικασίας. Αλλά αυτό ισχύει για κάθε πρακτική ανθρώπινη δραστηριότητα. Το ότι πρέπει να γράψεις grant proposals, να διεκδικήσεις πόρους, να δώσεις λόγο για το ερευνητικό σου πρόγραμμα, δεν σημαίνει ότι η δουλειά σου είναι κενή περιεχομένου. Βασικά συμβαίνι ακριβώς το αντίθετο. Η ερευνητική χρηματοδότηση σε καλεί να τεκμηριώσεις γιατί το ερώτημα που θέτεις αξίζει να απαντηθεί, όχι απαραίτητα γιατί θα παράγει προιόν. Και εδώ εντοπίζεται η διαφορά με το R&D σε εταιρείες. Δεν στοχεύει στο άμεσο κέρδος αλλά στην επέκταση της γνώσης ακόμα κι αν δεν ξέρεις εκ των προτέρων πού θα οδηγήσει.
Αν θέλουμε να καταλάβουμε τι σημαίνει αυτό, ας ξεκινήσουμε από κάτι που ίσως ενδιαφέρει γενικότερα λόγω του hype. ΑΙ και Large Language Models.
Από μικρά βήματα στα LLMs
Το να μιλάς με ένα Large Language Model σήμερα είναι σχεδόν μαγικό. Αλλά η μαγεία αυτή δεν γεννήθηκε προχθές. Είναι απλά ένας ακόμα κρίκος μιας αλυσίδας ερευνητικών βημάτων που ξεκινά αρκετά παλιά αλλά για να μην κάνουμε πλήρη ιστορική αναδρομή, ας το πιάσουμε από τις αρχές της δεκαετίας του 1990. Στις αρχές εκείνης της δεκαετίας, το Latent Semantic Analysis (LSA) ήταν απλά ένα εργαλείο για document retrieval. Χρησιμοποιούσε κάποιες τεχνικές από αριθμητική ανάλυση ώστε να αναπαραστήσει λέξεις και κείμενα σε κοινό διανυσματικό χώρο. Κανείς δεν είχε στο νου του GPTs, αλλά η ιδέα ότι οι λέξεις μπορούν να αναπαρίστανται ως σημεία σε ένα χώρο ήταν η αρχή για όλα τα embeddings που ακολούθησαν. Το 2013, το word2vec άλλαξε εντελώς το πεδίο του Natural Language Processing (NLP). Ο Mikolov et al (
Λίγο πιο γενικά ιστορικά
Μετασχηματισμός Fourier
Το 1965, οι Cooley και Tukey παρουσίασαν τον Fast Fourier Transform (FFT). Στην εποχή τους, ήταν καθαρά μαθηματικό/υπολογιστικό εργαλείο και για δεκαετίες, ελάχιστοι εκτός μαθηματικών και μηχανικών σήματος ενδιαφέρθηκαν. Σήμερα, ο FFT είναι κρυμμένος σε κάθε JPEG, MP3, και streaming. Όταν συμπιέζεις μια εικόνα ή ένα τραγούδι, οι συντελεστές Fourier κάνουν τη δουλειά. Χωρίς τη θεωρητική δουλειά του 65, η ψηφιακή εικόνα και ήχος δεν θα ήταν εφικτά όπως τα ξέρουμε.
Θεωρία Ramsey και distributed computing
Η θεωρία Ramsey από τα 30s εξετάζει πόσο μεγάλο πρέπει να είναι ένα σύνολο για να εγγυάται ότι θα εμφανιστεί μια συγκεκριμένη δομή. Για δεκαετίες ήταν καθαρά θεωρητική. Βασικά ήταν χρήσιμη σε combinatorics και γραφήματα. Σήμερα, τα θεμελιώδη αποτελέσματά της εφαρμόζονται στην ασφάλεια distributed συστημάτων και στην ανοχή σε σφάλματα.
Θεωρία πληροφορίας
Το 1948, ο Claude Shannon δημοσίευσε το "A Mathematical Theory of Communication". Δεν υπήρχε καμία εμπορική εφαρμογή. Τα τηλέφωνα ήταν αναλογικά και φυσικά το internet δεν υπήρχε. Σήμερα, κάθε μορφή ψηφιακής επικοινωνίας (WiFi, 4G, 5G, Internet) στηρίζεται στις αρχές του Shannon. Όλη η ψηφιακή εποχή χρωστά σε έναν άνθρωπο που τότε έγραφε "άχρηστη" μαθηματική θεωρία.
Γενικά
Markov Chains (1906) -> PageRank, Google Search
Graph theory (Euler, 1736) -> δίκτυα, routing, logistics
Κρυπτογραφία: το παιχνίδι της υπομονής
Αυτό είναι το δικό μου πεδίο οπότε μπορώ να μιλήσω με πολύ μεγαλύτερη ευκολία και να απαντήσω σε ερωτήσεις. Η κρυπτογραφία δείχνει ακόμη πιο καθαρά γιατί η έρευνα δεν πρέπει να κρίνεται μόνο με βάση το άμεσο αποτέλεσμα.
Το 1976, οι Diffie και Hellman παρουσίασαν τον πρώτο αλγόριθμο δημόσιας ανταλλαγής κλειδιών. Δηλαδή για πρώτη φορά μπορούσες να ανταλλάξεις κλειδιά για κρυπτογράφηση χωρίς να χρειάζεται να συναντήσεις κάποιον. Είναι μία πολύ έξυπνη ιδέα, αλλά πρακτικά πολύ αργή. Το 1977, το RSA έκανε το ίδιο για την κρυπτογράφηση. Δηλαδή μπορούσες να πάρεις το δημόσιο κλειδί κάποιου και να του στείλεις ένα μυστικό μήνυμα και μόνο εκείνος με το ιδιωτικό κλειδί θα μπορούσε να το διαβάσει. Και τα δύο έμειναν για χρόνια σαν "θεωρητικές πολυτέλειες". Σήμερα είναι τα θεμέλια κάθε ασφαλούς σύνδεσης σε οτιδήποτε κάνεις στο internet.
Στα 80ς είχαμε μία τρομερή ανακάλυψη. Τις αποδείξεις μηδενικής γνώσης. Γενικά αν θέλω να αποδείξω κάτι σε κάποιον, τότε ο πιο έυκολος τρόπος είναι να του δείξω αυτό το κάτι. Τι γίνεται όμως αν δεν θέλω να αποκαλύψω αυτό το "κάτι"; Αν είναι μυστικό; Τα Zero Knowledge Proofs έδειξαν ότι μπορείς να αποδείξεις ότι ξέρεις κάτι χωρίς να το αποκαλύψεις. Για δεκαετίες ήταν απλά θεωρία. Σήμερα είναι τεχνολογικό θεμέλιο σε blockchains, ψηφιακές ταυτότητες, ιδιωτικές ψηφοφορίες κλπ.
Στα 90ς ο γίγαντας Ajtai παρουσίασε μία συγκεκριμένη δυσκολία σε ένα μαθηματικό πρόβλημα. Το 2005, ο Regev χρησιμοποίησε αυτό το γεγονός και πρότεινε το Learning With Errors, που έγινε βάση για post-quantum κρυπτογραφία. Δηλαδή για κρυπτογραφία που θα ήταν ασφαλής απέναντι σε κβαντικούς υπολογιστές. Η έρευνα πάνω σε αλγόριθμους κβαντικών υπολογιστών είναι ακόμα ένα παράδειγμα έρευνας που *ίσως* βρει έδαφος σε αρκετά χρόνια από τώρα.
Το 2009, ο Gentry παρουσίασε το Fully Homomorphic Encryption δηλαδή να μπορούμε να υπολογίσουμε οποιαδήποτε συνάρτηση σε κρυπτογραφημένα δεδομένα. Παράλληλα, το multi-party computation εξελίχθηκε από "α κοίτα τι μπορώ να κάνω εντελώς θεωρητικά" Yao (1982) μέχρι τώρα που έχουμε libraries, καθιστώντας ασφαλείς υπολογισμούς πραγματικότητα.
Κάθε μία από αυτές τις τεχνολογίες ήταν κάποτε "άχρηστη". Τώρα είναι αόρατες υποδομές του Internet.
Η έρευνα ως κατανόηση, όχι μόνο ως προiόν
Η οικονομική λογική θέλει την έρευνα να έχει "απόδοση επένδυσης". Αλλά η επιστήμη δεν γεννήθηκε για να παράγει προiόντα. Γεννήθηκε για να κατανοεί τον κόσμο. K κάνουμε υποθέσεις, τις ελέγχουμε, αποτυγχάνουν, μαθαίνουμε. Ο Kuhn μας λέει ότι τα μεγάλα άλματα (paradigm shifts) έρχονται σπάνια, και προετοιμάζονται από χρόνια κανονικής, "βαρετής" επιστήμης. Ο Feyerabend τόνισε ότι η έρευνα χρειάζεται ελευθερία να κινείται και σε "άχρηστες" κατευθύνσεις γιατί δεν ξέρουμε από πού θα έρθει η επόμενη ιδέα.
Η εικασία του Collatz μπορεί να μην φτιάξει ποτέ καλύτερα κινητά. Αλλά η προσπάθεια να λυθεί μπορεί να φέρει νέα εργαλεία στη θεωρία αριθμών, που θα βρουν εφαρμογή εκεί που δεν το περιμέναμε. Btw θεωρία αριθμών πρέπει να μελετούσαν οι άνθρωποι για 2000 χρόνια (από αρχαία Ελλάδα μέχρι Fermat, Euler, Gauss) μέχρι να βρει εφαρμογή στο RSA που λέγαμε πιο πάνω.
Για να το κάνω και λίγο προσωπικό, στην τελευταία μου δημοσίευση δημιουργήσαμε έναν καινούριο τύπο Pseudorandom Generator (γεννήτρια τυχαιότητας). H βασική εφαρμογή του είναι πως είναι ένα θεωρητικά πιο "απλό" αντικείμενο από τους παλιούς και άρα μπορείς να έχεις κάποια αποτελέσματα με μικρότερη πολυπλοκότητα. Είναι χρήσιμο αυτό; Δεν ξέρω, ο καιρός θα δείξει. Θα χρησιμοποιηθεί άμεσα στο UNIX για να παράγει τυχαίους αριθμούς; Φυσικά και όχι.
Ένα οικοσύστημα ιδεών
Όταν κρίνουμε την έρευνα από το σήμερα, το 99% της μπορεί να φαίνεται ασήμαντο. Αλλά χωρίς αυτό το 99%, δεν θα υπήρχε το 1% που αλλάζει τα πάντα. Και επειδή δεν ξέρουμε ποιο είναι αυτό το 1%, πρέπει να καλλιεργούμε ολόκληρο το οικοσύστημα.
Η έρευνα είναι ο σπόρος και το engineering είναι ο φρούτο. Κι αν κοιτάμε μόνο τα φρούτα τότε ξεχνάμε ότι κάποιος έπρεπε να φυτέψει το δέντρο χρόνια πριν.
Ευχαριστώ όποιον διάβασε











 )
)


 BasketForum – Ιστορικό Αρχείο
BasketForum – Ιστορικό Αρχείο